Collation e encoding em bancos de dados
Introdução
Toda informação em um computador é armazenada e processada na sua representação em número binário.
Mas e os textos? Um texto é uma seqüência de caractéres, um caractér sendo uma letra ou um símbolo. Cada caractér é representado por um número binário, sendo que o mapeamento caractér-número é chamado de encoding.
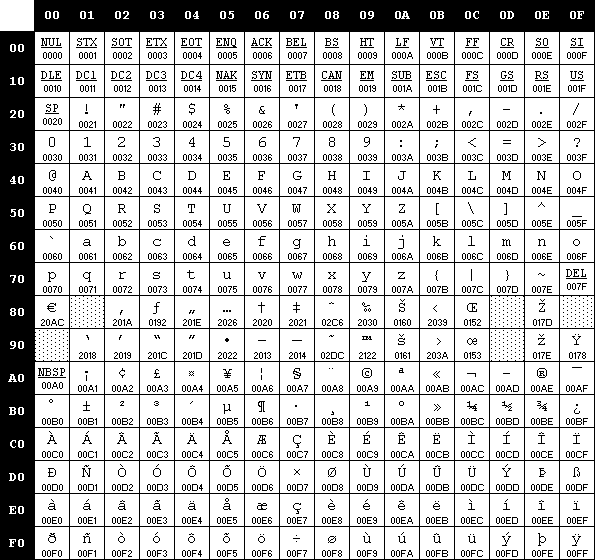
A tabela abaixo é do encoding Windows-1252, que contempla 255 caractéres possíveis, cada um representado por um byte. Você pode ver essa tabela com o Mapa de Caractéres do Windows (Win+R, charmap).
A collation, por sua vez, é a regra de ordenação usada para comparar textos. Ela também determina qual é o encoding utilizado para armazenamento.
No Microsoft SQL Server, no nome de uma collation, CI / CS significa case (in)sensitive — diferenciação por maiúsculas e minúsculas; AI / AS, accent (in)sensitive — diferenciação por acentos. Com uma collation case-insensitive (CI), por exemplo, tanto faz pesquisar silva ou SILVA. Com uma collation accent-insensitive (AI), Acucar e Açúcar são considerados iguais em comparações.
Accent-insensitive na verdade é insensível para todos os diacríticos de um idioma, como cedilhas (ç, ş) e acentos (é, ã, ô, etc). Algumas collations mais antigas não cobrem todos os diacríticos nas comparações (link), por isso, collations mais novas são preferíveis.
SELECT
[Name],
COLLATIONPROPERTY( [Name], 'LCID' ) AS [LCID],
COLLATIONPROPERTY( [Name], 'CodePage' ) AS [CodePage]
FROM sys.fn_helpcollations()
ORDER BY [Name];
| Nome | Encoding | Compara casing | Compara acentos |
|---|---|---|---|
| Latin1_General_ CI_AS | Windows-1252 | Não | Sim |
| Latin1_General_ 100_CI_AS_ KS_SC_UTF8 | UTF-8 (65001) | Não | Sim |
| Latin1_General_ 100_CS_AS_ KS_SC_UTF8 | UTF-8 (65001) | Sim | Sim |
Unicode, UTF-8 e UTF-16
O Unicode é uma tabela que define um número para cada caractér, compreendendo símbolos, algarismos e letras de diversos alfabetos. O número atribuído a um caractér é chamado de code point.
O UTF-8 e o UTF-16 são encodings que seguem o Unicode. Basicamente, são formas de armazenar esses números em bytes.
O UTF-16 usa 2 bytes para a maioria dos caractéres e 4 para aqueles acima do intervalo padrão. Esse encoding é usado nas strings da maioria das linguagens de programação.
O UTF-8 usa uma quantidade variável de bytes, de 1 a 4 por caractér. É o principal encoding da Internet.
| Intervalo Unicode | Grupos | Bytes por char, UTF-8 | Bytes por char, UTF-16 |
|---|---|---|---|
| 0x0000 a 0x007F | Alfabeto latino básico, algarismos arábicos (0 a 9), símbolos básicos do teclado | 1 | 2 |
| 0x0080 a 0x07FF | Alfabetos latino estendido (com acentos, cedilhas), grego, cirílico, árabe, hebraico | 2 | 2 |
| 0x0800 a 0xFFFF | Ideogramas japoneses e chineses; símbolos variados; operadores matemáticos | 3 | 2 |
| 0x010000 a 0x10FFFF | Pictogramas de escritas antigas (ex.: hieróglifos egípcios); emojis; símbolos musicais | 4 | 4 |
A escolha do encoding afeta diretamente o tamanho usado para armazenamento de textos. Se a maioria dos caractéres estiver no intervalo de alfabeto latino básico, o UTF-8 é melhor, porque usa menos bytes do que o UTF-16; mas, se a escrita for asiática, o UTF-16 tem vantagem, pois o caractér ocupa 2 bytes, contra 3 do UTF-8.
A tabela abaixo mostra como um número Unicode é convertido para UTF-8 ou UTF-16, para cada intervalo acima.
| Caractér de exemplo | Code point em binário | Em UTF-8 | Em UTF-16 |
|---|---|---|---|
| P (0x0050) | 00110010 | 00110010 | 00000000 00110010 |
| Ω (0x03A9) | 00000011 10101001 | 11001110 10101001 | 00000011 10101001 |
| € (0x20AC) | 00100000 10101100 | 11100010 10000010 10101100 | 00100000 10101100 |
| 🐎 (0x1F40E) | 00000001 11110100 00001110 | 11110000 10011111 10010000 10001110 | 11011000 00111101 11011100 00001110 |
A lógica do UTF-16 para code points acima de 0x010000 é:
U = code point
W1 = 2 bytes superiores
W2 = 2 bytes inferiores
W = U - 0x10000
W = yyyyyyyyyyxxxxxxxxxx (20 dígitos binários)
W1 = 110110yy yyyyyyyy
W2 = 110111xx xxxxxxxx
-> não há risco de W1 e W2 serem encarados como
outros caracteres porque o intervalo possível deles
é protegido na tabela Unicode.
Textos em bancos de dados SQL
CHAR e NCHAR recebem textos de tamanhos fixos; já o VARCHAR e o NVARCHAR aceitam tamanhos variáveis.
NCHAR e NVARCHAR são tipos presentes no SQL Server e o 'N' indica que eles armazenam o texto em codificação UTF-16. Já o CHAR e VARCHAR armazenam conforme o encoding da collation do banco.
Na declaração de tipo de coluna, é especificado o tamanho aceito por ela, por exemplo, NVARCHAR(n). É muito comum as pessoas pensarem que n é o tamanho em caractéres, mas isso não é verdade. Para CHAR e VARCHAR, n define o tamanho em bytes; para NCHAR e NVARCHAR, n é o tamanho em pares de bytes (x2).
Exemplo prático
Temos dois bancos de dados, um com collation Latin1_General_CI_AS (encoding Windows-1252) e outro com a collation Latin1_General_100_CI_AS_KS_SC_UTF8 (encoding UTF-8). Para cada um deles, vamos comparar o armazenamento entre VARCHAR e NVARCHAR, para textos em alfabeto latino básico, latino estendido, grego e emojis. Segue o script para executar:
CREATE TABLE [dbo].[Pessoa] (
[Nome] VARCHAR(24) NOT NULL,
[NomeUtf16] NVARCHAR(24) NOT NULL
);
INSERT INTO [dbo].[Pessoa] VALUES
('Pericles','Pericles'), -- latino sem acento
('Péricles','Péricles'), -- latino com acento
(N'Περικλῆς',N'Περικλῆς'), -- grego
(N'美しいキモノ',N'美しいキモノ'), -- japonês katakana
(N'Papai Noel 🎅',N'Papai Noel 🎅'); -- com emoji
-- o prefixo N é necessário para strings unicode
SELECT
[Nome], DATALENGTH([Nome]) AS [TamanhoEmBytes],
[NomeUtf16], DATALENGTH([NomeUtf16]) AS [TamanhoEmBytes]
FROM [dbo].[Pessoa];
DROP TABLE [dbo].[Pessoa];
Latin1 General CI AS
| Nome VARCHAR | Tamanho em bytes | Nome NVARCHAR | Tamanho em bytes |
|---|---|---|---|
| Pericles | 8 | Pericles | 16 |
| Péricles | 8 | Péricles | 16 |
| ?e?????? | 8 | Περικλῆς | 16 |
| ?????? | 6 | 美しいキモノ | 12 |
| Papai Noel ?? | 13 | Papai Noel 🎅 | 26 |
Podemos perceber que o encoding Windows-1252 não suporta caractéres gregos, japoneses e emojis, que são substituídos por '?'. Apesar disso, consegue atender muito bem palavras latinas, gastando apenas 1 byte por letra, mesmo naquelas com acentos ou cedilhas.
Latin1 General 100 CI AS KS SC UTF8
| Nome VARCHAR | Tamanho em bytes | Nome NVARCHAR | Tamanho em bytes |
|---|---|---|---|
| Pericles | 8 | Pericles | 16 |
| Péricles | 9 | Péricles | 16 |
| Περικλῆς | 17 | Περικλῆς | 16 |
| 美しいキモノ | 18 | 美しいキモノ | 12 |
| Papai Noel 🎅 | 15 | Papai Noel 🎅 | 26 |
Com a collation UTF-8, o campo VARCHAR suportou com sucesso todos os caractéres e teve maior eficiência em geral. O terceiro nome, Περικλῆς, precisou de 17 bytes porque a letra ῆ (unicode 0x1FC6) é do grego antigo e requer 3 bytes em UTF-8. Para japonês katakana, UTF-16 provou-se mais eficiente.
Fontes e leituras interessantes
A
AlexandreHTRBCampinas / SP,
Brasil