Collation and encoding in databases
Introduction
Every information in a computer is stored and processed in its binary number representation.
But what about texts? A text is a sequence of characters, a character being a letter or a symbol. Each character is represented by a binary number and the character-number mapping is called encoding.
The table below is for Windows-1252 encoding, which addresses 255 possible characters, each represented by one byte. You can see this table on Windows Character Map (Win+R, charmap).
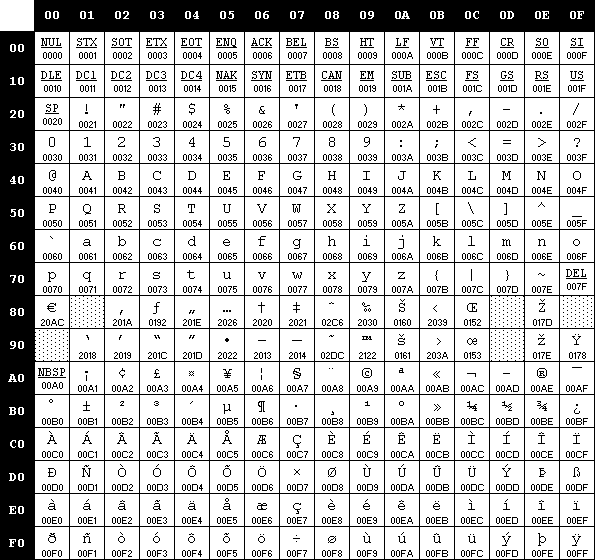
The collation is the ordering and comparison rule for texts. It also determines which encoding is used for storage.
On Microsoft SQL Server, in the collation's name, CI / CS means case (in)sensitive; AI / AS, accent (in)sensitive. With a case-insensitive (CI) collation, for example, searching for either silva or SILVA yields the same results; with an accent-insensitive (AI) collation, Acucar and Açúcar are considered equal for comparisons.
Accent-insensitive is insensitive actually for all the diacritics of a language, like cedillas (ç, ş) and accents (é, ã, ô, etc). Some older collations do not cover all diacritics on comparisons (link), so newer collations should be preferred.
SELECT
[Name],
COLLATIONPROPERTY( [Name], 'LCID' ) AS [LCID],
COLLATIONPROPERTY( [Name], 'CodePage' ) AS [CodePage]
FROM sys.fn_helpcollations()
ORDER BY [Name];
| Name | Encoding | Compares casing | Compares accents |
|---|---|---|---|
| Latin1_General_ CI_AS | Windows-1252 | No | Yes |
| Latin1_General_ 100_CI_AS_ KS_SC_UTF8 | UTF-8 (65001) | No | Yes |
| Latin1_General_ 100_CS_AS_ KS_SC_UTF8 | UTF-8 (65001) | Yes | Yes |
Unicode, UTF-8 and UTF-16
Unicode is a table that defines a number for each character, covering symbols, digits and letters from many languages. The number attributed to a character is called code point.
UTF-8 and UTF-16 are encodings that follow Unicode. Basically, they are ways of storing those numbers into bytes.
UTF-16 uses 2 bytes for most chars and 4 for those above the standard range. This encoding is used in the strings of most programming languages.
UTF-8 uses a variable number of bytes, starting at 1 and up to 4 for a char. It's the main encoding on the Internet.
| Unicode range | Groups | Bytes per char, UTF-8 | Bytes per char, UTF-16 |
|---|---|---|---|
| 0x0000 - 0x007F | Basic latin alphabet, arabic digits (0-9), basic keyboard symbols | 1 | 2 |
| 0x0080 - 0x07FF | Extended latin alphabet, greek, cyrillic, arabic, hebrew | 2 | 2 |
| 0x0800 - 0xFFFF | Japanese and chinese ideograms; varied symbols; math operators | 3 | 2 |
| 0x010000 - 0x10FFFF | Ancient writing pictograms (e.g. egyptian hieroglyphs); emojis; musical symbols | 4 | 4 |
The choice of encoding directly affects the size of text storage. If most characters lie in the basic latin range, UTF-8 is better, because it uses fewer bytes than UTF-16; however, if it's an asian text, UTF-16 is the best, because each character occupies 2 bytes, instead of 3 on UTF-8.
The table below shows how an Unicode number is converted to UTF-8 or UTF-16, for each range above.
| Example character | Code point, in binary | In UTF-8 | In UTF-16 |
|---|---|---|---|
| P (0x0050) | 00110010 | 00110010 | 00000000 00110010 |
| Ω (0x03A9) | 00000011 10101001 | 11001110 10101001 | 00000011 10101001 |
| € (0x20AC) | 00100000 10101100 | 11100010 10000010 10101100 | 00100000 10101100 |
| 🐎 (0x1F40E) | 00000001 11110100 00001110 | 11110000 10011111 10010000 10001110 | 11011000 00111101 11011100 00001110 |
The logic for UTF-16 code points above 0x010000 is:
U = code point
W1 = 2 upper bytes
W2 = 2 lower bytes
W = U - 0x10000
W = yyyyyyyyyyxxxxxxxxxx (20 binary digits)
W1 = 110110yy yyyyyyyy
W2 = 110111xx xxxxxxxx
-> there is no risk of W1 and W2 being mistaken for
other characters because the possible interval for them
is protected on the Unicode table.
Texts in SQL databases
CHAR and NCHAR store fixed-size texts; VARCHAR and NVARCHAR store variable-sized texts.
NCHAR and NVARCHAR are types present on SQL Server and the 'N' indicates that they store text in UTF-16 encoding. CHAR and VARCHAR, on the other hand, store according to the encoding of the database's collation.
The storage size is specified on the column type declaration, such as NVARCHAR(n). Many people think that n is the number of characters, but that is not true. For CHAR and VARCHAR, n defines the size in bytes; for NCHAR and NVARCHAR, n is the size in byte-pairs (x2).
Practical example
Let's have two databases, one with the Latin1_General_CI_AS collation (Windows-1252 encoding) and another with Latin1_General_100_CI_AS_KS_SC_UTF8 collation (UTF-8 encoding). For each of them, we will compare the storage sizes between VARCHAR and NVARCHAR, for texts in basic and extended latin alphabet, greek, japanese and emojis. Below, the script to run:
CREATE TABLE [dbo].[Person] (
[Name] VARCHAR(24) NOT NULL,
[NameUtf16] NVARCHAR(24) NOT NULL
);
INSERT INTO [dbo].[Person] VALUES
('Pericles','Pericles'), -- latin without accent
('Péricles','Péricles'), -- latin with accent
(N'Περικλῆς',N'Περικλῆς'), -- greek
(N'美しいキモノ',N'美しいキモノ'), -- japanese katakana
(N'Santa Claus 🎅',N'Santa Claus 🎅'); -- with emoji
-- the N prefix is necessary for unicode strings
SELECT
[Name], DATALENGTH([Name]) AS [SizeInBytes],
[NameUtf16], DATALENGTH([NameUtf16]) AS [SizeInBytes]
FROM [dbo].[Person];
DROP TABLE [dbo].[Person];
Latin1 General CI AS
| VARCHAR name | Size in bytes | NVARCHAR name | Size in bytes |
|---|---|---|---|
| Pericles | 8 | Pericles | 16 |
| Péricles | 8 | Péricles | 16 |
| ?e?????? | 8 | Περικλῆς | 16 |
| ?????? | 6 | 美しいキモノ | 12 |
| Santa Claus ?? | 14 | Santa Claus 🎅 | 28 |
Note that Windows-1252 encoding does not support greek and japanese characters, nor emojis, that are replaced by '?'. Despite that, it handles very well latin words, with only 1 byte per letter, even on those with accents or cedillas.
Latin1 General 100 CI AS KS SC UTF8
| VARCHAR name | Size in bytes | NVARCHAR name | Size in bytes |
|---|---|---|---|
| Pericles | 8 | Pericles | 16 |
| Péricles | 9 | Péricles | 16 |
| Περικλῆς | 17 | Περικλῆς | 16 |
| 美しいキモノ | 18 | 美しいキモノ | 12 |
| Santa Claus 🎅 | 16 | Santa Claus 🎅 | 28 |
With an UTF-8 collation, the VARCHAR field successfully supported all characters and had a higher efficiency for most cases. The third name, Περικλῆς, needed 17 bytes because the letter ῆ (unicode 0x1FC6) is from ancient greek and requires 3 bytes in UTF-8 encoding. For japanese katakana, UTF-16 proved more efficient.
Sources and interesting reads
A
AlexandreHTRBCampinas / SP,
Brasil